USE CASE: How to Build a Reusable GenAI Prompt Library on a Repeatable Prompt Anatomy for an Online Store
A real-world GenAI marketing use case: how a lean luxury jewelry team stopped prompting every task from scratch, by defining the anatomy a good prompt is built from, then making that anatomy the backbone of a named, reusable prompt library.
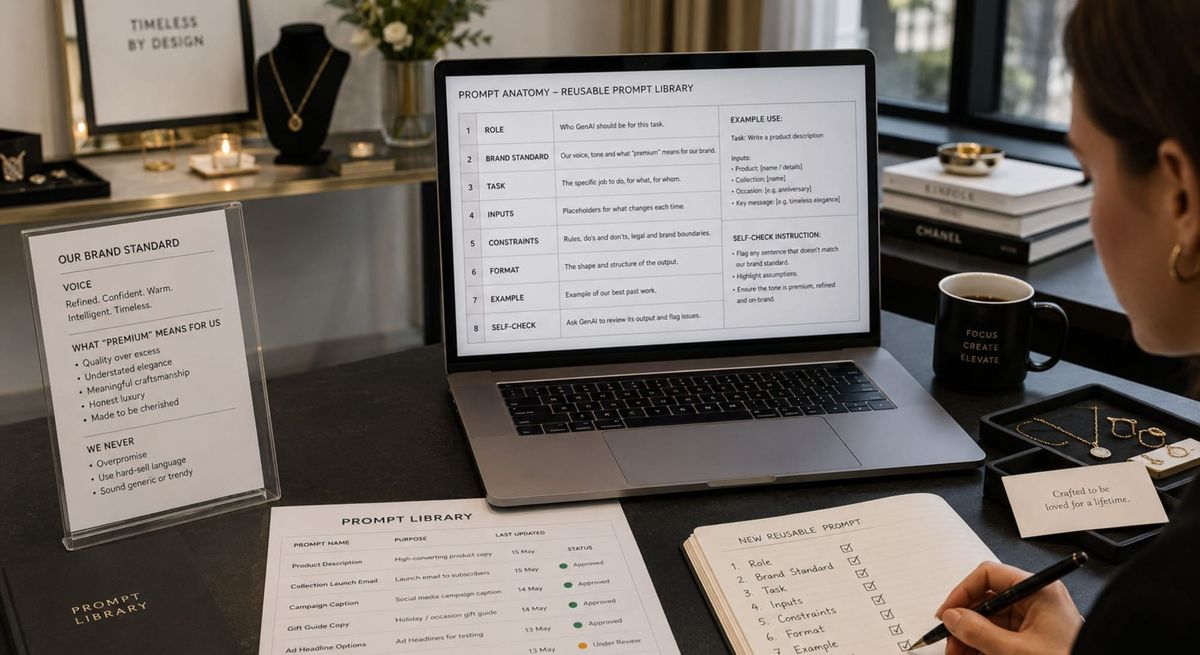
A prompt anatomy is the backbone of everything else: the named parts a good prompt is always built from. Get the anatomy right and a reusable library becomes possible; skip it and you are left with prompt chaos. This is what building on a prompt anatomy looks like in practice: how a lean luxury jewelry team made its GenAI output consistent by giving every prompt the same structure.
The Context: Everyone Prompting, No Two the Same
A premium, branded online jewelry store with a lean marketing team, all of them using GenAI daily: for product descriptions, launch emails, campaign captions, the lot. Nobody was short of GenAI; what they lacked was any shared way of building a prompt. Every request started from a blank box and whatever the person remembered to type that day.
The Challenge: Prompt Chaos Is Really Anatomy Chaos
The chaos looked like wording – everyone phrasing requests differently – but underneath it was structural. A prompt like “write a product description” has no role, no brand standard, no constraints, no format, no example: most of its anatomy is simply missing, so the model fills the gaps with guesses, and the output swings from on-brand to off, from premium to generic, week to week. 2 people could prompt the same job 5 different ways in a single week because there was no agreed shape for what a prompt should contain. The inconsistency wasn’t bad luck; it was missing anatomy. And in luxury, that is fatal, because consistency is the product; a lean team cannot afford to reinvent the structure of quality every time it opens a chat.
A prompt is a structure, not a sentence: Prompt chaos is really anatomy chaos: every request a different shape, the same parts missing. The lasting skill isn’t a clever prompt, that expires the moment the model changes; it’s knowing the anatomy a good prompt is always built from. Fix the anatomy and reuse, consistency and a real library all follow.
The GenAI Workflow: Define the Anatomy, Then Build the Library on It
The fix pivoted on one thing: naming the anatomy a prompt should always have, and then building every reusable prompt to it. Instead of collecting clever prompts, the team agreed the parts a complete prompt contains – the backbone below – and made “is every part present?” the test a prompt had to pass before it earned a place in the library.
1. Role. Who GenAI should be for this task – “you are our brand’s copywriter”, not an anonymous assistant.
2. Brand standard. The encoded voice and what “premium” means for this brand: the one part GenAI cannot supply, and the part one-off prompts always omit.
3. Task. The specific job, stated unambiguously: what to produce, for what, for whom.
4. Inputs. Clear placeholders for the parts that change each run – the product, the offer, the occasion – so the same prompt flexes without being rewritten.
5. Constraints. The rules: forbidden phrasings, legal lines, claims you never make, the do’s and don’ts.
6. Format. The shape of the output – length, structure, sections – so it lands usable, not reshaped by hand.
7. Example. A piece of your best past work, to anchor the quality bar in something real rather than a description.
8. Self-check. An instruction to flag where it has drifted off-brand and to mark anything it assumed – the part that keeps the prompt honest.
With the anatomy named, the library built itself: for each repeated task, the team filled in all eight parts once, named the prompt for its job, and tested it. GenAI did the drafting and refining – proposing each component, turning the team’s best one-off prompts into fully-formed ones, stress-testing each against real cases – while the team supplied the part GenAI couldn’t: the brand standard. From then on, anyone reaching for GenAI started from a complete, named prompt rather than a half-built blank box, and the output stopped swinging.
You are helping build a reusable prompt for a premium jewelry brand’s marketing, using a fixed prompt anatomy. Here is the repeated task – [task] – examples of our best past output, and our brand voice and standards: [paste].
Draft one reusable prompt for this task with EVERY part of the anatomy present and labelled: Role, Brand standard, Task, Inputs (as placeholders), Constraints, Format, Example, Self-check. Encode what “premium” means for us — not generic luxury clichés.
Then stress-test it on two real cases and flag any part that is thin or would drift off-brand, so we fix it before it enters the library. Use only the standard I gave you — do NOT invent brand voice. Mark anything you’re assuming as CONFIRM WITH ME.
The caveat that decides whether this works. A complete anatomy makes a prompt powerful, and a library makes that power scale, which is also the danger: a subtly off-brand prompt, reused everywhere, multiplies one small error into a consistent one, so a prompt earns its place only after it’s tested, never on first draft. Two parts of the anatomy matter most here. The brand standard is the one component GenAI cannot fill — ask it and it returns “timeless elegance, exquisite craftsmanship”, clichés true of every jeweller — so that part must come from you, every time. And the self-check exists because GenAI drifts confidently; it is the anatomy admitting the model needs watching. Two more: the anatomy is durable, but any given prompt is not; wording goes stale as the brand evolves and the models change, so the library needs an owner and a review rhythm. And the inputs part is what keeps consistency from becoming uniformity – same anatomy, different specifics – so the prompt is a structure to fill, not a cutter that stamps everything identical.
The Result: Every Prompt the Same Shape
Prompt chaos became a prompt system, because every prompt now had the same anatomy. The same task started from the same complete, named prompt, so the output stopped swinging between on-brand and off, which for a luxury brand is the whole game. The lean team stopped rebuilding the structure of quality every time it opened a chat: the eight parts were filled in once per task, captured in the library, and reused by everyone. New work, and new hands, started from a proven shape rather than a blank box. And because the anatomy always carried the brand standard, more GenAI use meant more consistency, not less. No invented figures here: the change is that the durable asset wasn’t a clever prompt, which expires, it was the anatomy underneath every one of them, which doesn’t.
Recommended KPIs to Follow
A prompt system is judged on consistency and leverage — does the output stop swinging, and does the team stop rebuilding the structure each time? Here’s where the evidence sits and the direction this work should push things. The point is the direction of travel, not a promised number.
Anatomy Completeness & Reuse
The share of GenAI tasks started from a named library prompt with the full anatomy present – every part filled, nothing missing – rather than a half-built one-off. It’s the direct read on whether the backbone is actually being used.
Benchmark: No public figure, an internal metric; list your repeat tasks, score how many run from a complete-anatomy library prompt today, and track that coverage climbing.
Output consistency (on-brand rate)
The goal: the share of GenAI output that lands on-brand first time instead of swinging premium-to-generic. A complete anatomy – especially the brand-standard part – is what holds the line; for a luxury brand this is the metric that matters most.
Benchmark: No clean public figure, internal; note that general-purpose GenAI output tends to need editing to reflect a brand’s voice and “rarely provides the precision marketing teams need at scale” without being grounded in your own standards, which is exactly what the anatomy encodes (Databricks).
Time per Task
The leverage: time per task should fall as a complete, named prompt replaces rebuilding the anatomy from scratch each time. Watch it drop while consistency holds, that gap is the point of the system.
Benchmark: For context, businesses using GenAI report markedly faster content production – on the order of ~60% faster – and most marketers say it saves them more than an hour a day on creative tasks; a reusable anatomy compounds that by removing the rebuild-every-time tax (HubSpot; Typeface).
Completeness and time saved are the leverage; the on-brand rate is the point. Watch them together, speed that comes from dropping parts of the anatomy isn’t the win. Track your own trend; the benchmarks are context.
Why this Transfers
Any team where everyone prompts and no two prompts share a shape has the same hidden problem: GenAI use that scales effort but not consistency. The transferable move is to define the anatomy a prompt should always have: role, standard, task, inputs, constraints, format, example, self-check — and build every reusable prompt to it. The clever wording expires when the model changes; the anatomy is the part that lasts.
Recommended Articles:
